mirror of https://github.com/grafana/loki
fix(deps): update module github.com/parquet-go/parquet-go to v0.25.1 (main) (#18013)
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>pull/18016/head
parent
9d850faf3d
commit
97ea2b60b2
@ -1,15 +0,0 @@ |
||||
# Created by .ignore support plugin (hsz.mobi) |
||||
### Go template |
||||
# Binaries for programs and plugins |
||||
*.exe |
||||
*.exe~ |
||||
*.dll |
||||
*.so |
||||
*.dylib |
||||
|
||||
# Test binary, build with `go test -c` |
||||
*.test |
||||
|
||||
# Output of the go coverage tool, specifically when used with LiteIDE |
||||
*.out |
||||
|
||||
@ -1,22 +0,0 @@ |
||||
language: go |
||||
arch: |
||||
- ppc64le |
||||
- amd64 |
||||
go: |
||||
- 1.3 |
||||
- 1.4 |
||||
- 1.5 |
||||
- 1.6 |
||||
- 1.7 |
||||
- 1.8 |
||||
- 1.9 |
||||
- "1.10" |
||||
- tip |
||||
jobs: |
||||
exclude : |
||||
- arch : ppc64le |
||||
go : |
||||
- 1.3 |
||||
- arch : ppc64le |
||||
go : |
||||
- 1.4 |
||||
@ -1,19 +0,0 @@ |
||||
Copyright (C) 2014 by Oleku Konko |
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy |
||||
of this software and associated documentation files (the "Software"), to deal |
||||
in the Software without restriction, including without limitation the rights |
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell |
||||
copies of the Software, and to permit persons to whom the Software is |
||||
furnished to do so, subject to the following conditions: |
||||
|
||||
The above copyright notice and this permission notice shall be included in |
||||
all copies or substantial portions of the Software. |
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR |
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, |
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE |
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER |
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, |
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN |
||||
THE SOFTWARE. |
||||
@ -1,431 +0,0 @@ |
||||
ASCII Table Writer |
||||
========= |
||||
|
||||
[](https://travis-ci.org/olekukonko/tablewriter) |
||||
[](https://sourcegraph.com/github.com/olekukonko/tablewriter) |
||||
[](https://godoc.org/github.com/olekukonko/tablewriter) |
||||
|
||||
Generate ASCII table on the fly ... Installation is simple as |
||||
|
||||
go get github.com/olekukonko/tablewriter |
||||
|
||||
|
||||
#### Features |
||||
- Automatic Padding |
||||
- Support Multiple Lines |
||||
- Supports Alignment |
||||
- Support Custom Separators |
||||
- Automatic Alignment of numbers & percentage |
||||
- Write directly to http , file etc via `io.Writer` |
||||
- Read directly from CSV file |
||||
- Optional row line via `SetRowLine` |
||||
- Normalise table header |
||||
- Make CSV Headers optional |
||||
- Enable or disable table border |
||||
- Set custom footer support |
||||
- Optional identical cells merging |
||||
- Set custom caption |
||||
- Optional reflowing of paragraphs in multi-line cells. |
||||
|
||||
#### Example 1 - Basic |
||||
```go |
||||
data := [][]string{ |
||||
[]string{"A", "The Good", "500"}, |
||||
[]string{"B", "The Very very Bad Man", "288"}, |
||||
[]string{"C", "The Ugly", "120"}, |
||||
[]string{"D", "The Gopher", "800"}, |
||||
} |
||||
|
||||
table := tablewriter.NewWriter(os.Stdout) |
||||
table.SetHeader([]string{"Name", "Sign", "Rating"}) |
||||
|
||||
for _, v := range data { |
||||
table.Append(v) |
||||
} |
||||
table.Render() // Send output |
||||
``` |
||||
|
||||
##### Output 1 |
||||
``` |
||||
+------+-----------------------+--------+ |
||||
| NAME | SIGN | RATING | |
||||
+------+-----------------------+--------+ |
||||
| A | The Good | 500 | |
||||
| B | The Very very Bad Man | 288 | |
||||
| C | The Ugly | 120 | |
||||
| D | The Gopher | 800 | |
||||
+------+-----------------------+--------+ |
||||
``` |
||||
|
||||
#### Example 2 - Without Border / Footer / Bulk Append |
||||
```go |
||||
data := [][]string{ |
||||
[]string{"1/1/2014", "Domain name", "2233", "$10.98"}, |
||||
[]string{"1/1/2014", "January Hosting", "2233", "$54.95"}, |
||||
[]string{"1/4/2014", "February Hosting", "2233", "$51.00"}, |
||||
[]string{"1/4/2014", "February Extra Bandwidth", "2233", "$30.00"}, |
||||
} |
||||
|
||||
table := tablewriter.NewWriter(os.Stdout) |
||||
table.SetHeader([]string{"Date", "Description", "CV2", "Amount"}) |
||||
table.SetFooter([]string{"", "", "Total", "$146.93"}) // Add Footer |
||||
table.SetBorder(false) // Set Border to false |
||||
table.AppendBulk(data) // Add Bulk Data |
||||
table.Render() |
||||
``` |
||||
|
||||
##### Output 2 |
||||
``` |
||||
|
||||
DATE | DESCRIPTION | CV2 | AMOUNT |
||||
-----------+--------------------------+-------+---------- |
||||
1/1/2014 | Domain name | 2233 | $10.98 |
||||
1/1/2014 | January Hosting | 2233 | $54.95 |
||||
1/4/2014 | February Hosting | 2233 | $51.00 |
||||
1/4/2014 | February Extra Bandwidth | 2233 | $30.00 |
||||
-----------+--------------------------+-------+---------- |
||||
TOTAL | $146 93 |
||||
--------+---------- |
||||
|
||||
``` |
||||
|
||||
|
||||
#### Example 3 - CSV |
||||
```go |
||||
table, _ := tablewriter.NewCSV(os.Stdout, "testdata/test_info.csv", true) |
||||
table.SetAlignment(tablewriter.ALIGN_LEFT) // Set Alignment |
||||
table.Render() |
||||
``` |
||||
|
||||
##### Output 3 |
||||
``` |
||||
+----------+--------------+------+-----+---------+----------------+ |
||||
| FIELD | TYPE | NULL | KEY | DEFAULT | EXTRA | |
||||
+----------+--------------+------+-----+---------+----------------+ |
||||
| user_id | smallint(5) | NO | PRI | NULL | auto_increment | |
||||
| username | varchar(10) | NO | | NULL | | |
||||
| password | varchar(100) | NO | | NULL | | |
||||
+----------+--------------+------+-----+---------+----------------+ |
||||
``` |
||||
|
||||
#### Example 4 - Custom Separator |
||||
```go |
||||
table, _ := tablewriter.NewCSV(os.Stdout, "testdata/test.csv", true) |
||||
table.SetRowLine(true) // Enable row line |
||||
|
||||
// Change table lines |
||||
table.SetCenterSeparator("*") |
||||
table.SetColumnSeparator("╪") |
||||
table.SetRowSeparator("-") |
||||
|
||||
table.SetAlignment(tablewriter.ALIGN_LEFT) |
||||
table.Render() |
||||
``` |
||||
|
||||
##### Output 4 |
||||
``` |
||||
*------------*-----------*---------* |
||||
╪ FIRST NAME ╪ LAST NAME ╪ SSN ╪ |
||||
*------------*-----------*---------* |
||||
╪ John ╪ Barry ╪ 123456 ╪ |
||||
*------------*-----------*---------* |
||||
╪ Kathy ╪ Smith ╪ 687987 ╪ |
||||
*------------*-----------*---------* |
||||
╪ Bob ╪ McCornick ╪ 3979870 ╪ |
||||
*------------*-----------*---------* |
||||
``` |
||||
|
||||
#### Example 5 - Markdown Format |
||||
```go |
||||
data := [][]string{ |
||||
[]string{"1/1/2014", "Domain name", "2233", "$10.98"}, |
||||
[]string{"1/1/2014", "January Hosting", "2233", "$54.95"}, |
||||
[]string{"1/4/2014", "February Hosting", "2233", "$51.00"}, |
||||
[]string{"1/4/2014", "February Extra Bandwidth", "2233", "$30.00"}, |
||||
} |
||||
|
||||
table := tablewriter.NewWriter(os.Stdout) |
||||
table.SetHeader([]string{"Date", "Description", "CV2", "Amount"}) |
||||
table.SetBorders(tablewriter.Border{Left: true, Top: false, Right: true, Bottom: false}) |
||||
table.SetCenterSeparator("|") |
||||
table.AppendBulk(data) // Add Bulk Data |
||||
table.Render() |
||||
``` |
||||
|
||||
##### Output 5 |
||||
``` |
||||
| DATE | DESCRIPTION | CV2 | AMOUNT | |
||||
|----------|--------------------------|------|--------| |
||||
| 1/1/2014 | Domain name | 2233 | $10.98 | |
||||
| 1/1/2014 | January Hosting | 2233 | $54.95 | |
||||
| 1/4/2014 | February Hosting | 2233 | $51.00 | |
||||
| 1/4/2014 | February Extra Bandwidth | 2233 | $30.00 | |
||||
``` |
||||
|
||||
#### Example 6 - Identical cells merging |
||||
```go |
||||
data := [][]string{ |
||||
[]string{"1/1/2014", "Domain name", "1234", "$10.98"}, |
||||
[]string{"1/1/2014", "January Hosting", "2345", "$54.95"}, |
||||
[]string{"1/4/2014", "February Hosting", "3456", "$51.00"}, |
||||
[]string{"1/4/2014", "February Extra Bandwidth", "4567", "$30.00"}, |
||||
} |
||||
|
||||
table := tablewriter.NewWriter(os.Stdout) |
||||
table.SetHeader([]string{"Date", "Description", "CV2", "Amount"}) |
||||
table.SetFooter([]string{"", "", "Total", "$146.93"}) |
||||
table.SetAutoMergeCells(true) |
||||
table.SetRowLine(true) |
||||
table.AppendBulk(data) |
||||
table.Render() |
||||
``` |
||||
|
||||
##### Output 6 |
||||
``` |
||||
+----------+--------------------------+-------+---------+ |
||||
| DATE | DESCRIPTION | CV2 | AMOUNT | |
||||
+----------+--------------------------+-------+---------+ |
||||
| 1/1/2014 | Domain name | 1234 | $10.98 | |
||||
+ +--------------------------+-------+---------+ |
||||
| | January Hosting | 2345 | $54.95 | |
||||
+----------+--------------------------+-------+---------+ |
||||
| 1/4/2014 | February Hosting | 3456 | $51.00 | |
||||
+ +--------------------------+-------+---------+ |
||||
| | February Extra Bandwidth | 4567 | $30.00 | |
||||
+----------+--------------------------+-------+---------+ |
||||
| TOTAL | $146 93 | |
||||
+----------+--------------------------+-------+---------+ |
||||
``` |
||||
|
||||
#### Example 7 - Identical cells merging (specify the column index to merge) |
||||
```go |
||||
data := [][]string{ |
||||
[]string{"1/1/2014", "Domain name", "1234", "$10.98"}, |
||||
[]string{"1/1/2014", "January Hosting", "1234", "$10.98"}, |
||||
[]string{"1/4/2014", "February Hosting", "3456", "$51.00"}, |
||||
[]string{"1/4/2014", "February Extra Bandwidth", "4567", "$30.00"}, |
||||
} |
||||
|
||||
table := tablewriter.NewWriter(os.Stdout) |
||||
table.SetHeader([]string{"Date", "Description", "CV2", "Amount"}) |
||||
table.SetFooter([]string{"", "", "Total", "$146.93"}) |
||||
table.SetAutoMergeCellsByColumnIndex([]int{2, 3}) |
||||
table.SetRowLine(true) |
||||
table.AppendBulk(data) |
||||
table.Render() |
||||
``` |
||||
|
||||
##### Output 7 |
||||
``` |
||||
+----------+--------------------------+-------+---------+ |
||||
| DATE | DESCRIPTION | CV2 | AMOUNT | |
||||
+----------+--------------------------+-------+---------+ |
||||
| 1/1/2014 | Domain name | 1234 | $10.98 | |
||||
+----------+--------------------------+ + + |
||||
| 1/1/2014 | January Hosting | | | |
||||
+----------+--------------------------+-------+---------+ |
||||
| 1/4/2014 | February Hosting | 3456 | $51.00 | |
||||
+----------+--------------------------+-------+---------+ |
||||
| 1/4/2014 | February Extra Bandwidth | 4567 | $30.00 | |
||||
+----------+--------------------------+-------+---------+ |
||||
| TOTAL | $146.93 | |
||||
+----------+--------------------------+-------+---------+ |
||||
``` |
||||
|
||||
|
||||
#### Table with color |
||||
```go |
||||
data := [][]string{ |
||||
[]string{"1/1/2014", "Domain name", "2233", "$10.98"}, |
||||
[]string{"1/1/2014", "January Hosting", "2233", "$54.95"}, |
||||
[]string{"1/4/2014", "February Hosting", "2233", "$51.00"}, |
||||
[]string{"1/4/2014", "February Extra Bandwidth", "2233", "$30.00"}, |
||||
} |
||||
|
||||
table := tablewriter.NewWriter(os.Stdout) |
||||
table.SetHeader([]string{"Date", "Description", "CV2", "Amount"}) |
||||
table.SetFooter([]string{"", "", "Total", "$146.93"}) // Add Footer |
||||
table.SetBorder(false) // Set Border to false |
||||
|
||||
table.SetHeaderColor(tablewriter.Colors{tablewriter.Bold, tablewriter.BgGreenColor}, |
||||
tablewriter.Colors{tablewriter.FgHiRedColor, tablewriter.Bold, tablewriter.BgBlackColor}, |
||||
tablewriter.Colors{tablewriter.BgRedColor, tablewriter.FgWhiteColor}, |
||||
tablewriter.Colors{tablewriter.BgCyanColor, tablewriter.FgWhiteColor}) |
||||
|
||||
table.SetColumnColor(tablewriter.Colors{tablewriter.Bold, tablewriter.FgHiBlackColor}, |
||||
tablewriter.Colors{tablewriter.Bold, tablewriter.FgHiRedColor}, |
||||
tablewriter.Colors{tablewriter.Bold, tablewriter.FgHiBlackColor}, |
||||
tablewriter.Colors{tablewriter.Bold, tablewriter.FgBlackColor}) |
||||
|
||||
table.SetFooterColor(tablewriter.Colors{}, tablewriter.Colors{}, |
||||
tablewriter.Colors{tablewriter.Bold}, |
||||
tablewriter.Colors{tablewriter.FgHiRedColor}) |
||||
|
||||
table.AppendBulk(data) |
||||
table.Render() |
||||
``` |
||||
|
||||
#### Table with color Output |
||||
 |
||||
|
||||
#### Example - 8 Table Cells with Color |
||||
|
||||
Individual Cell Colors from `func Rich` take precedence over Column Colors |
||||
|
||||
```go |
||||
data := [][]string{ |
||||
[]string{"Test1Merge", "HelloCol2 - 1", "HelloCol3 - 1", "HelloCol4 - 1"}, |
||||
[]string{"Test1Merge", "HelloCol2 - 2", "HelloCol3 - 2", "HelloCol4 - 2"}, |
||||
[]string{"Test1Merge", "HelloCol2 - 3", "HelloCol3 - 3", "HelloCol4 - 3"}, |
||||
[]string{"Test2Merge", "HelloCol2 - 4", "HelloCol3 - 4", "HelloCol4 - 4"}, |
||||
[]string{"Test2Merge", "HelloCol2 - 5", "HelloCol3 - 5", "HelloCol4 - 5"}, |
||||
[]string{"Test2Merge", "HelloCol2 - 6", "HelloCol3 - 6", "HelloCol4 - 6"}, |
||||
[]string{"Test2Merge", "HelloCol2 - 7", "HelloCol3 - 7", "HelloCol4 - 7"}, |
||||
[]string{"Test3Merge", "HelloCol2 - 8", "HelloCol3 - 8", "HelloCol4 - 8"}, |
||||
[]string{"Test3Merge", "HelloCol2 - 9", "HelloCol3 - 9", "HelloCol4 - 9"}, |
||||
[]string{"Test3Merge", "HelloCol2 - 10", "HelloCol3 -10", "HelloCol4 - 10"}, |
||||
} |
||||
|
||||
table := tablewriter.NewWriter(os.Stdout) |
||||
table.SetHeader([]string{"Col1", "Col2", "Col3", "Col4"}) |
||||
table.SetFooter([]string{"", "", "Footer3", "Footer4"}) |
||||
table.SetBorder(false) |
||||
|
||||
table.SetHeaderColor(tablewriter.Colors{tablewriter.Bold, tablewriter.BgGreenColor}, |
||||
tablewriter.Colors{tablewriter.FgHiRedColor, tablewriter.Bold, tablewriter.BgBlackColor}, |
||||
tablewriter.Colors{tablewriter.BgRedColor, tablewriter.FgWhiteColor}, |
||||
tablewriter.Colors{tablewriter.BgCyanColor, tablewriter.FgWhiteColor}) |
||||
|
||||
table.SetColumnColor(tablewriter.Colors{tablewriter.Bold, tablewriter.FgHiBlackColor}, |
||||
tablewriter.Colors{tablewriter.Bold, tablewriter.FgHiRedColor}, |
||||
tablewriter.Colors{tablewriter.Bold, tablewriter.FgHiBlackColor}, |
||||
tablewriter.Colors{tablewriter.Bold, tablewriter.FgBlackColor}) |
||||
|
||||
table.SetFooterColor(tablewriter.Colors{}, tablewriter.Colors{}, |
||||
tablewriter.Colors{tablewriter.Bold}, |
||||
tablewriter.Colors{tablewriter.FgHiRedColor}) |
||||
|
||||
colorData1 := []string{"TestCOLOR1Merge", "HelloCol2 - COLOR1", "HelloCol3 - COLOR1", "HelloCol4 - COLOR1"} |
||||
colorData2 := []string{"TestCOLOR2Merge", "HelloCol2 - COLOR2", "HelloCol3 - COLOR2", "HelloCol4 - COLOR2"} |
||||
|
||||
for i, row := range data { |
||||
if i == 4 { |
||||
table.Rich(colorData1, []tablewriter.Colors{tablewriter.Colors{}, tablewriter.Colors{tablewriter.Normal, tablewriter.FgCyanColor}, tablewriter.Colors{tablewriter.Bold, tablewriter.FgWhiteColor}, tablewriter.Colors{}}) |
||||
table.Rich(colorData2, []tablewriter.Colors{tablewriter.Colors{tablewriter.Normal, tablewriter.FgMagentaColor}, tablewriter.Colors{}, tablewriter.Colors{tablewriter.Bold, tablewriter.BgRedColor}, tablewriter.Colors{tablewriter.FgHiGreenColor, tablewriter.Italic, tablewriter.BgHiCyanColor}}) |
||||
} |
||||
table.Append(row) |
||||
} |
||||
|
||||
table.SetAutoMergeCells(true) |
||||
table.Render() |
||||
|
||||
``` |
||||
|
||||
##### Table cells with color Output |
||||
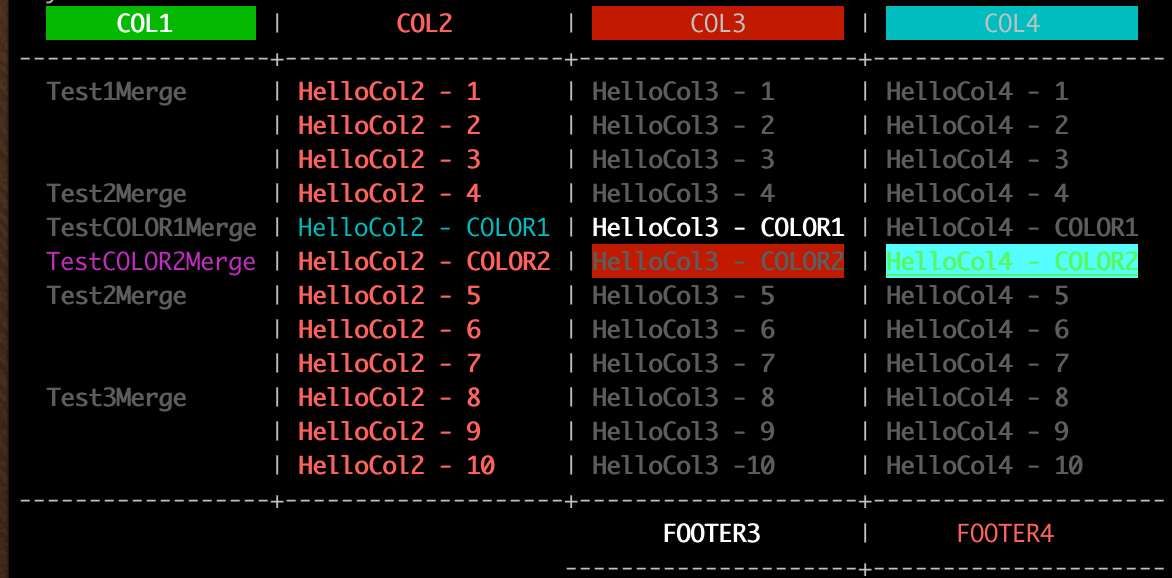 |
||||
|
||||
#### Example 9 - Set table caption |
||||
```go |
||||
data := [][]string{ |
||||
[]string{"A", "The Good", "500"}, |
||||
[]string{"B", "The Very very Bad Man", "288"}, |
||||
[]string{"C", "The Ugly", "120"}, |
||||
[]string{"D", "The Gopher", "800"}, |
||||
} |
||||
|
||||
table := tablewriter.NewWriter(os.Stdout) |
||||
table.SetHeader([]string{"Name", "Sign", "Rating"}) |
||||
table.SetCaption(true, "Movie ratings.") |
||||
|
||||
for _, v := range data { |
||||
table.Append(v) |
||||
} |
||||
table.Render() // Send output |
||||
``` |
||||
|
||||
Note: Caption text will wrap with total width of rendered table. |
||||
|
||||
##### Output 9 |
||||
``` |
||||
+------+-----------------------+--------+ |
||||
| NAME | SIGN | RATING | |
||||
+------+-----------------------+--------+ |
||||
| A | The Good | 500 | |
||||
| B | The Very very Bad Man | 288 | |
||||
| C | The Ugly | 120 | |
||||
| D | The Gopher | 800 | |
||||
+------+-----------------------+--------+ |
||||
Movie ratings. |
||||
``` |
||||
|
||||
#### Example 10 - Set NoWhiteSpace and TablePadding option |
||||
```go |
||||
data := [][]string{ |
||||
{"node1.example.com", "Ready", "compute", "1.11"}, |
||||
{"node2.example.com", "Ready", "compute", "1.11"}, |
||||
{"node3.example.com", "Ready", "compute", "1.11"}, |
||||
{"node4.example.com", "NotReady", "compute", "1.11"}, |
||||
} |
||||
|
||||
table := tablewriter.NewWriter(os.Stdout) |
||||
table.SetHeader([]string{"Name", "Status", "Role", "Version"}) |
||||
table.SetAutoWrapText(false) |
||||
table.SetAutoFormatHeaders(true) |
||||
table.SetHeaderAlignment(ALIGN_LEFT) |
||||
table.SetAlignment(ALIGN_LEFT) |
||||
table.SetCenterSeparator("") |
||||
table.SetColumnSeparator("") |
||||
table.SetRowSeparator("") |
||||
table.SetHeaderLine(false) |
||||
table.SetBorder(false) |
||||
table.SetTablePadding("\t") // pad with tabs |
||||
table.SetNoWhiteSpace(true) |
||||
table.AppendBulk(data) // Add Bulk Data |
||||
table.Render() |
||||
``` |
||||
|
||||
##### Output 10 |
||||
``` |
||||
NAME STATUS ROLE VERSION |
||||
node1.example.com Ready compute 1.11 |
||||
node2.example.com Ready compute 1.11 |
||||
node3.example.com Ready compute 1.11 |
||||
node4.example.com NotReady compute 1.11 |
||||
``` |
||||
|
||||
#### Render table into a string |
||||
|
||||
Instead of rendering the table to `io.Stdout` you can also render it into a string. Go 1.10 introduced the `strings.Builder` type which implements the `io.Writer` interface and can therefore be used for this task. Example: |
||||
|
||||
```go |
||||
package main |
||||
|
||||
import ( |
||||
"strings" |
||||
"fmt" |
||||
|
||||
"github.com/olekukonko/tablewriter" |
||||
) |
||||
|
||||
func main() { |
||||
tableString := &strings.Builder{} |
||||
table := tablewriter.NewWriter(tableString) |
||||
|
||||
/* |
||||
* Code to fill the table |
||||
*/ |
||||
|
||||
table.Render() |
||||
|
||||
fmt.Println(tableString.String()) |
||||
} |
||||
``` |
||||
|
||||
#### TODO |
||||
- ~~Import Directly from CSV~~ - `done` |
||||
- ~~Support for `SetFooter`~~ - `done` |
||||
- ~~Support for `SetBorder`~~ - `done` |
||||
- ~~Support table with uneven rows~~ - `done` |
||||
- ~~Support custom alignment~~ |
||||
- General Improvement & Optimisation |
||||
- `NewHTML` Parse table from HTML |
||||
@ -1,52 +0,0 @@ |
||||
// Copyright 2014 Oleku Konko All rights reserved.
|
||||
// Use of this source code is governed by a MIT
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
// This module is a Table Writer API for the Go Programming Language.
|
||||
// The protocols were written in pure Go and works on windows and unix systems
|
||||
|
||||
package tablewriter |
||||
|
||||
import ( |
||||
"encoding/csv" |
||||
"io" |
||||
"os" |
||||
) |
||||
|
||||
// Start A new table by importing from a CSV file
|
||||
// Takes io.Writer and csv File name
|
||||
func NewCSV(writer io.Writer, fileName string, hasHeader bool) (*Table, error) { |
||||
file, err := os.Open(fileName) |
||||
if err != nil { |
||||
return &Table{}, err |
||||
} |
||||
defer file.Close() |
||||
csvReader := csv.NewReader(file) |
||||
t, err := NewCSVReader(writer, csvReader, hasHeader) |
||||
return t, err |
||||
} |
||||
|
||||
// Start a New Table Writer with csv.Reader
|
||||
// This enables customisation such as reader.Comma = ';'
|
||||
// See http://golang.org/src/pkg/encoding/csv/reader.go?s=3213:3671#L94
|
||||
func NewCSVReader(writer io.Writer, csvReader *csv.Reader, hasHeader bool) (*Table, error) { |
||||
t := NewWriter(writer) |
||||
if hasHeader { |
||||
// Read the first row
|
||||
headers, err := csvReader.Read() |
||||
if err != nil { |
||||
return &Table{}, err |
||||
} |
||||
t.SetHeader(headers) |
||||
} |
||||
for { |
||||
record, err := csvReader.Read() |
||||
if err == io.EOF { |
||||
break |
||||
} else if err != nil { |
||||
return &Table{}, err |
||||
} |
||||
t.Append(record) |
||||
} |
||||
return t, nil |
||||
} |
||||
@ -1,967 +0,0 @@ |
||||
// Copyright 2014 Oleku Konko All rights reserved.
|
||||
// Use of this source code is governed by a MIT
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
// This module is a Table Writer API for the Go Programming Language.
|
||||
// The protocols were written in pure Go and works on windows and unix systems
|
||||
|
||||
// Create & Generate text based table
|
||||
package tablewriter |
||||
|
||||
import ( |
||||
"bytes" |
||||
"fmt" |
||||
"io" |
||||
"regexp" |
||||
"strings" |
||||
) |
||||
|
||||
const ( |
||||
MAX_ROW_WIDTH = 30 |
||||
) |
||||
|
||||
const ( |
||||
CENTER = "+" |
||||
ROW = "-" |
||||
COLUMN = "|" |
||||
SPACE = " " |
||||
NEWLINE = "\n" |
||||
) |
||||
|
||||
const ( |
||||
ALIGN_DEFAULT = iota |
||||
ALIGN_CENTER |
||||
ALIGN_RIGHT |
||||
ALIGN_LEFT |
||||
) |
||||
|
||||
var ( |
||||
decimal = regexp.MustCompile(`^-?(?:\d{1,3}(?:,\d{3})*|\d+)(?:\.\d+)?$`) |
||||
percent = regexp.MustCompile(`^-?\d+\.?\d*$%$`) |
||||
) |
||||
|
||||
type Border struct { |
||||
Left bool |
||||
Right bool |
||||
Top bool |
||||
Bottom bool |
||||
} |
||||
|
||||
type Table struct { |
||||
out io.Writer |
||||
rows [][]string |
||||
lines [][][]string |
||||
cs map[int]int |
||||
rs map[int]int |
||||
headers [][]string |
||||
footers [][]string |
||||
caption bool |
||||
captionText string |
||||
autoFmt bool |
||||
autoWrap bool |
||||
reflowText bool |
||||
mW int |
||||
pCenter string |
||||
pRow string |
||||
pColumn string |
||||
tColumn int |
||||
tRow int |
||||
hAlign int |
||||
fAlign int |
||||
align int |
||||
newLine string |
||||
rowLine bool |
||||
autoMergeCells bool |
||||
columnsToAutoMergeCells map[int]bool |
||||
noWhiteSpace bool |
||||
tablePadding string |
||||
hdrLine bool |
||||
borders Border |
||||
colSize int |
||||
headerParams []string |
||||
columnsParams []string |
||||
footerParams []string |
||||
columnsAlign []int |
||||
} |
||||
|
||||
// Start New Table
|
||||
// Take io.Writer Directly
|
||||
func NewWriter(writer io.Writer) *Table { |
||||
t := &Table{ |
||||
out: writer, |
||||
rows: [][]string{}, |
||||
lines: [][][]string{}, |
||||
cs: make(map[int]int), |
||||
rs: make(map[int]int), |
||||
headers: [][]string{}, |
||||
footers: [][]string{}, |
||||
caption: false, |
||||
captionText: "Table caption.", |
||||
autoFmt: true, |
||||
autoWrap: true, |
||||
reflowText: true, |
||||
mW: MAX_ROW_WIDTH, |
||||
pCenter: CENTER, |
||||
pRow: ROW, |
||||
pColumn: COLUMN, |
||||
tColumn: -1, |
||||
tRow: -1, |
||||
hAlign: ALIGN_DEFAULT, |
||||
fAlign: ALIGN_DEFAULT, |
||||
align: ALIGN_DEFAULT, |
||||
newLine: NEWLINE, |
||||
rowLine: false, |
||||
hdrLine: true, |
||||
borders: Border{Left: true, Right: true, Bottom: true, Top: true}, |
||||
colSize: -1, |
||||
headerParams: []string{}, |
||||
columnsParams: []string{}, |
||||
footerParams: []string{}, |
||||
columnsAlign: []int{}} |
||||
return t |
||||
} |
||||
|
||||
// Render table output
|
||||
func (t *Table) Render() { |
||||
if t.borders.Top { |
||||
t.printLine(true) |
||||
} |
||||
t.printHeading() |
||||
if t.autoMergeCells { |
||||
t.printRowsMergeCells() |
||||
} else { |
||||
t.printRows() |
||||
} |
||||
if !t.rowLine && t.borders.Bottom { |
||||
t.printLine(true) |
||||
} |
||||
t.printFooter() |
||||
|
||||
if t.caption { |
||||
t.printCaption() |
||||
} |
||||
} |
||||
|
||||
const ( |
||||
headerRowIdx = -1 |
||||
footerRowIdx = -2 |
||||
) |
||||
|
||||
// Set table header
|
||||
func (t *Table) SetHeader(keys []string) { |
||||
t.colSize = len(keys) |
||||
for i, v := range keys { |
||||
lines := t.parseDimension(v, i, headerRowIdx) |
||||
t.headers = append(t.headers, lines) |
||||
} |
||||
} |
||||
|
||||
// Set table Footer
|
||||
func (t *Table) SetFooter(keys []string) { |
||||
//t.colSize = len(keys)
|
||||
for i, v := range keys { |
||||
lines := t.parseDimension(v, i, footerRowIdx) |
||||
t.footers = append(t.footers, lines) |
||||
} |
||||
} |
||||
|
||||
// Set table Caption
|
||||
func (t *Table) SetCaption(caption bool, captionText ...string) { |
||||
t.caption = caption |
||||
if len(captionText) == 1 { |
||||
t.captionText = captionText[0] |
||||
} |
||||
} |
||||
|
||||
// Turn header autoformatting on/off. Default is on (true).
|
||||
func (t *Table) SetAutoFormatHeaders(auto bool) { |
||||
t.autoFmt = auto |
||||
} |
||||
|
||||
// Turn automatic multiline text adjustment on/off. Default is on (true).
|
||||
func (t *Table) SetAutoWrapText(auto bool) { |
||||
t.autoWrap = auto |
||||
} |
||||
|
||||
// Turn automatic reflowing of multiline text when rewrapping. Default is on (true).
|
||||
func (t *Table) SetReflowDuringAutoWrap(auto bool) { |
||||
t.reflowText = auto |
||||
} |
||||
|
||||
// Set the Default column width
|
||||
func (t *Table) SetColWidth(width int) { |
||||
t.mW = width |
||||
} |
||||
|
||||
// Set the minimal width for a column
|
||||
func (t *Table) SetColMinWidth(column int, width int) { |
||||
t.cs[column] = width |
||||
} |
||||
|
||||
// Set the Column Separator
|
||||
func (t *Table) SetColumnSeparator(sep string) { |
||||
t.pColumn = sep |
||||
} |
||||
|
||||
// Set the Row Separator
|
||||
func (t *Table) SetRowSeparator(sep string) { |
||||
t.pRow = sep |
||||
} |
||||
|
||||
// Set the center Separator
|
||||
func (t *Table) SetCenterSeparator(sep string) { |
||||
t.pCenter = sep |
||||
} |
||||
|
||||
// Set Header Alignment
|
||||
func (t *Table) SetHeaderAlignment(hAlign int) { |
||||
t.hAlign = hAlign |
||||
} |
||||
|
||||
// Set Footer Alignment
|
||||
func (t *Table) SetFooterAlignment(fAlign int) { |
||||
t.fAlign = fAlign |
||||
} |
||||
|
||||
// Set Table Alignment
|
||||
func (t *Table) SetAlignment(align int) { |
||||
t.align = align |
||||
} |
||||
|
||||
// Set No White Space
|
||||
func (t *Table) SetNoWhiteSpace(allow bool) { |
||||
t.noWhiteSpace = allow |
||||
} |
||||
|
||||
// Set Table Padding
|
||||
func (t *Table) SetTablePadding(padding string) { |
||||
t.tablePadding = padding |
||||
} |
||||
|
||||
func (t *Table) SetColumnAlignment(keys []int) { |
||||
for _, v := range keys { |
||||
switch v { |
||||
case ALIGN_CENTER: |
||||
break |
||||
case ALIGN_LEFT: |
||||
break |
||||
case ALIGN_RIGHT: |
||||
break |
||||
default: |
||||
v = ALIGN_DEFAULT |
||||
} |
||||
t.columnsAlign = append(t.columnsAlign, v) |
||||
} |
||||
} |
||||
|
||||
// Set New Line
|
||||
func (t *Table) SetNewLine(nl string) { |
||||
t.newLine = nl |
||||
} |
||||
|
||||
// Set Header Line
|
||||
// This would enable / disable a line after the header
|
||||
func (t *Table) SetHeaderLine(line bool) { |
||||
t.hdrLine = line |
||||
} |
||||
|
||||
// Set Row Line
|
||||
// This would enable / disable a line on each row of the table
|
||||
func (t *Table) SetRowLine(line bool) { |
||||
t.rowLine = line |
||||
} |
||||
|
||||
// Set Auto Merge Cells
|
||||
// This would enable / disable the merge of cells with identical values
|
||||
func (t *Table) SetAutoMergeCells(auto bool) { |
||||
t.autoMergeCells = auto |
||||
} |
||||
|
||||
// Set Auto Merge Cells By Column Index
|
||||
// This would enable / disable the merge of cells with identical values for specific columns
|
||||
// If cols is empty, it is the same as `SetAutoMergeCells(true)`.
|
||||
func (t *Table) SetAutoMergeCellsByColumnIndex(cols []int) { |
||||
t.autoMergeCells = true |
||||
|
||||
if len(cols) > 0 { |
||||
m := make(map[int]bool) |
||||
for _, col := range cols { |
||||
m[col] = true |
||||
} |
||||
t.columnsToAutoMergeCells = m |
||||
} |
||||
} |
||||
|
||||
// Set Table Border
|
||||
// This would enable / disable line around the table
|
||||
func (t *Table) SetBorder(border bool) { |
||||
t.SetBorders(Border{border, border, border, border}) |
||||
} |
||||
|
||||
func (t *Table) SetBorders(border Border) { |
||||
t.borders = border |
||||
} |
||||
|
||||
// Append row to table
|
||||
func (t *Table) Append(row []string) { |
||||
rowSize := len(t.headers) |
||||
if rowSize > t.colSize { |
||||
t.colSize = rowSize |
||||
} |
||||
|
||||
n := len(t.lines) |
||||
line := [][]string{} |
||||
for i, v := range row { |
||||
|
||||
// Detect string width
|
||||
// Detect String height
|
||||
// Break strings into words
|
||||
out := t.parseDimension(v, i, n) |
||||
|
||||
// Append broken words
|
||||
line = append(line, out) |
||||
} |
||||
t.lines = append(t.lines, line) |
||||
} |
||||
|
||||
// Append row to table with color attributes
|
||||
func (t *Table) Rich(row []string, colors []Colors) { |
||||
rowSize := len(t.headers) |
||||
if rowSize > t.colSize { |
||||
t.colSize = rowSize |
||||
} |
||||
|
||||
n := len(t.lines) |
||||
line := [][]string{} |
||||
for i, v := range row { |
||||
|
||||
// Detect string width
|
||||
// Detect String height
|
||||
// Break strings into words
|
||||
out := t.parseDimension(v, i, n) |
||||
|
||||
if len(colors) > i { |
||||
color := colors[i] |
||||
out[0] = format(out[0], color) |
||||
} |
||||
|
||||
// Append broken words
|
||||
line = append(line, out) |
||||
} |
||||
t.lines = append(t.lines, line) |
||||
} |
||||
|
||||
// Allow Support for Bulk Append
|
||||
// Eliminates repeated for loops
|
||||
func (t *Table) AppendBulk(rows [][]string) { |
||||
for _, row := range rows { |
||||
t.Append(row) |
||||
} |
||||
} |
||||
|
||||
// NumLines to get the number of lines
|
||||
func (t *Table) NumLines() int { |
||||
return len(t.lines) |
||||
} |
||||
|
||||
// Clear rows
|
||||
func (t *Table) ClearRows() { |
||||
t.lines = [][][]string{} |
||||
} |
||||
|
||||
// Clear footer
|
||||
func (t *Table) ClearFooter() { |
||||
t.footers = [][]string{} |
||||
} |
||||
|
||||
// Center based on position and border.
|
||||
func (t *Table) center(i int) string { |
||||
if i == -1 && !t.borders.Left { |
||||
return t.pRow |
||||
} |
||||
|
||||
if i == len(t.cs)-1 && !t.borders.Right { |
||||
return t.pRow |
||||
} |
||||
|
||||
return t.pCenter |
||||
} |
||||
|
||||
// Print line based on row width
|
||||
func (t *Table) printLine(nl bool) { |
||||
fmt.Fprint(t.out, t.center(-1)) |
||||
for i := 0; i < len(t.cs); i++ { |
||||
v := t.cs[i] |
||||
fmt.Fprintf(t.out, "%s%s%s%s", |
||||
t.pRow, |
||||
strings.Repeat(string(t.pRow), v), |
||||
t.pRow, |
||||
t.center(i)) |
||||
} |
||||
if nl { |
||||
fmt.Fprint(t.out, t.newLine) |
||||
} |
||||
} |
||||
|
||||
// Print line based on row width with our without cell separator
|
||||
func (t *Table) printLineOptionalCellSeparators(nl bool, displayCellSeparator []bool) { |
||||
fmt.Fprint(t.out, t.pCenter) |
||||
for i := 0; i < len(t.cs); i++ { |
||||
v := t.cs[i] |
||||
if i > len(displayCellSeparator) || displayCellSeparator[i] { |
||||
// Display the cell separator
|
||||
fmt.Fprintf(t.out, "%s%s%s%s", |
||||
t.pRow, |
||||
strings.Repeat(string(t.pRow), v), |
||||
t.pRow, |
||||
t.pCenter) |
||||
} else { |
||||
// Don't display the cell separator for this cell
|
||||
fmt.Fprintf(t.out, "%s%s", |
||||
strings.Repeat(" ", v+2), |
||||
t.pCenter) |
||||
} |
||||
} |
||||
if nl { |
||||
fmt.Fprint(t.out, t.newLine) |
||||
} |
||||
} |
||||
|
||||
// Return the PadRight function if align is left, PadLeft if align is right,
|
||||
// and Pad by default
|
||||
func pad(align int) func(string, string, int) string { |
||||
padFunc := Pad |
||||
switch align { |
||||
case ALIGN_LEFT: |
||||
padFunc = PadRight |
||||
case ALIGN_RIGHT: |
||||
padFunc = PadLeft |
||||
} |
||||
return padFunc |
||||
} |
||||
|
||||
// Print heading information
|
||||
func (t *Table) printHeading() { |
||||
// Check if headers is available
|
||||
if len(t.headers) < 1 { |
||||
return |
||||
} |
||||
|
||||
// Identify last column
|
||||
end := len(t.cs) - 1 |
||||
|
||||
// Get pad function
|
||||
padFunc := pad(t.hAlign) |
||||
|
||||
// Checking for ANSI escape sequences for header
|
||||
is_esc_seq := false |
||||
if len(t.headerParams) > 0 { |
||||
is_esc_seq = true |
||||
} |
||||
|
||||
// Maximum height.
|
||||
max := t.rs[headerRowIdx] |
||||
|
||||
// Print Heading
|
||||
for x := 0; x < max; x++ { |
||||
// Check if border is set
|
||||
// Replace with space if not set
|
||||
if !t.noWhiteSpace { |
||||
fmt.Fprint(t.out, ConditionString(t.borders.Left, t.pColumn, SPACE)) |
||||
} |
||||
|
||||
for y := 0; y <= end; y++ { |
||||
v := t.cs[y] |
||||
h := "" |
||||
|
||||
if y < len(t.headers) && x < len(t.headers[y]) { |
||||
h = t.headers[y][x] |
||||
} |
||||
if t.autoFmt { |
||||
h = Title(h) |
||||
} |
||||
pad := ConditionString((y == end && !t.borders.Left), SPACE, t.pColumn) |
||||
if t.noWhiteSpace { |
||||
pad = ConditionString((y == end && !t.borders.Left), SPACE, t.tablePadding) |
||||
} |
||||
if is_esc_seq { |
||||
if !t.noWhiteSpace { |
||||
fmt.Fprintf(t.out, " %s %s", |
||||
format(padFunc(h, SPACE, v), |
||||
t.headerParams[y]), pad) |
||||
} else { |
||||
fmt.Fprintf(t.out, "%s %s", |
||||
format(padFunc(h, SPACE, v), |
||||
t.headerParams[y]), pad) |
||||
} |
||||
} else { |
||||
if !t.noWhiteSpace { |
||||
fmt.Fprintf(t.out, " %s %s", |
||||
padFunc(h, SPACE, v), |
||||
pad) |
||||
} else { |
||||
// the spaces between breaks the kube formatting
|
||||
fmt.Fprintf(t.out, "%s%s", |
||||
padFunc(h, SPACE, v), |
||||
pad) |
||||
} |
||||
} |
||||
} |
||||
// Next line
|
||||
fmt.Fprint(t.out, t.newLine) |
||||
} |
||||
if t.hdrLine { |
||||
t.printLine(true) |
||||
} |
||||
} |
||||
|
||||
// Print heading information
|
||||
func (t *Table) printFooter() { |
||||
// Check if headers is available
|
||||
if len(t.footers) < 1 { |
||||
return |
||||
} |
||||
|
||||
// Only print line if border is not set
|
||||
if !t.borders.Bottom { |
||||
t.printLine(true) |
||||
} |
||||
|
||||
// Identify last column
|
||||
end := len(t.cs) - 1 |
||||
|
||||
// Get pad function
|
||||
padFunc := pad(t.fAlign) |
||||
|
||||
// Checking for ANSI escape sequences for header
|
||||
is_esc_seq := false |
||||
if len(t.footerParams) > 0 { |
||||
is_esc_seq = true |
||||
} |
||||
|
||||
// Maximum height.
|
||||
max := t.rs[footerRowIdx] |
||||
|
||||
// Print Footer
|
||||
erasePad := make([]bool, len(t.footers)) |
||||
for x := 0; x < max; x++ { |
||||
// Check if border is set
|
||||
// Replace with space if not set
|
||||
fmt.Fprint(t.out, ConditionString(t.borders.Bottom, t.pColumn, SPACE)) |
||||
|
||||
for y := 0; y <= end; y++ { |
||||
v := t.cs[y] |
||||
f := "" |
||||
if y < len(t.footers) && x < len(t.footers[y]) { |
||||
f = t.footers[y][x] |
||||
} |
||||
if t.autoFmt { |
||||
f = Title(f) |
||||
} |
||||
pad := ConditionString((y == end && !t.borders.Top), SPACE, t.pColumn) |
||||
|
||||
if erasePad[y] || (x == 0 && len(f) == 0) { |
||||
pad = SPACE |
||||
erasePad[y] = true |
||||
} |
||||
|
||||
if is_esc_seq { |
||||
fmt.Fprintf(t.out, " %s %s", |
||||
format(padFunc(f, SPACE, v), |
||||
t.footerParams[y]), pad) |
||||
} else { |
||||
fmt.Fprintf(t.out, " %s %s", |
||||
padFunc(f, SPACE, v), |
||||
pad) |
||||
} |
||||
|
||||
//fmt.Fprintf(t.out, " %s %s",
|
||||
// padFunc(f, SPACE, v),
|
||||
// pad)
|
||||
} |
||||
// Next line
|
||||
fmt.Fprint(t.out, t.newLine) |
||||
//t.printLine(true)
|
||||
} |
||||
|
||||
hasPrinted := false |
||||
|
||||
for i := 0; i <= end; i++ { |
||||
v := t.cs[i] |
||||
pad := t.pRow |
||||
center := t.pCenter |
||||
length := len(t.footers[i][0]) |
||||
|
||||
if length > 0 { |
||||
hasPrinted = true |
||||
} |
||||
|
||||
// Set center to be space if length is 0
|
||||
if length == 0 && !t.borders.Right { |
||||
center = SPACE |
||||
} |
||||
|
||||
// Print first junction
|
||||
if i == 0 { |
||||
if length > 0 && !t.borders.Left { |
||||
center = t.pRow |
||||
} |
||||
fmt.Fprint(t.out, center) |
||||
} |
||||
|
||||
// Pad With space of length is 0
|
||||
if length == 0 { |
||||
pad = SPACE |
||||
} |
||||
// Ignore left space as it has printed before
|
||||
if hasPrinted || t.borders.Left { |
||||
pad = t.pRow |
||||
center = t.pCenter |
||||
} |
||||
|
||||
// Change Center end position
|
||||
if center != SPACE { |
||||
if i == end && !t.borders.Right { |
||||
center = t.pRow |
||||
} |
||||
} |
||||
|
||||
// Change Center start position
|
||||
if center == SPACE { |
||||
if i < end && len(t.footers[i+1][0]) != 0 { |
||||
if !t.borders.Left { |
||||
center = t.pRow |
||||
} else { |
||||
center = t.pCenter |
||||
} |
||||
} |
||||
} |
||||
|
||||
// Print the footer
|
||||
fmt.Fprintf(t.out, "%s%s%s%s", |
||||
pad, |
||||
strings.Repeat(string(pad), v), |
||||
pad, |
||||
center) |
||||
|
||||
} |
||||
|
||||
fmt.Fprint(t.out, t.newLine) |
||||
} |
||||
|
||||
// Print caption text
|
||||
func (t Table) printCaption() { |
||||
width := t.getTableWidth() |
||||
paragraph, _ := WrapString(t.captionText, width) |
||||
for linecount := 0; linecount < len(paragraph); linecount++ { |
||||
fmt.Fprintln(t.out, paragraph[linecount]) |
||||
} |
||||
} |
||||
|
||||
// Calculate the total number of characters in a row
|
||||
func (t Table) getTableWidth() int { |
||||
var chars int |
||||
for _, v := range t.cs { |
||||
chars += v |
||||
} |
||||
|
||||
// Add chars, spaces, seperators to calculate the total width of the table.
|
||||
// ncols := t.colSize
|
||||
// spaces := ncols * 2
|
||||
// seps := ncols + 1
|
||||
|
||||
return (chars + (3 * t.colSize) + 2) |
||||
} |
||||
|
||||
func (t Table) printRows() { |
||||
for i, lines := range t.lines { |
||||
t.printRow(lines, i) |
||||
} |
||||
} |
||||
|
||||
func (t *Table) fillAlignment(num int) { |
||||
if len(t.columnsAlign) < num { |
||||
t.columnsAlign = make([]int, num) |
||||
for i := range t.columnsAlign { |
||||
t.columnsAlign[i] = t.align |
||||
} |
||||
} |
||||
} |
||||
|
||||
// Print Row Information
|
||||
// Adjust column alignment based on type
|
||||
|
||||
func (t *Table) printRow(columns [][]string, rowIdx int) { |
||||
// Get Maximum Height
|
||||
max := t.rs[rowIdx] |
||||
total := len(columns) |
||||
|
||||
// TODO Fix uneven col size
|
||||
// if total < t.colSize {
|
||||
// for n := t.colSize - total; n < t.colSize ; n++ {
|
||||
// columns = append(columns, []string{SPACE})
|
||||
// t.cs[n] = t.mW
|
||||
// }
|
||||
//}
|
||||
|
||||
// Pad Each Height
|
||||
pads := []int{} |
||||
|
||||
// Checking for ANSI escape sequences for columns
|
||||
is_esc_seq := false |
||||
if len(t.columnsParams) > 0 { |
||||
is_esc_seq = true |
||||
} |
||||
t.fillAlignment(total) |
||||
|
||||
for i, line := range columns { |
||||
length := len(line) |
||||
pad := max - length |
||||
pads = append(pads, pad) |
||||
for n := 0; n < pad; n++ { |
||||
columns[i] = append(columns[i], " ") |
||||
} |
||||
} |
||||
//fmt.Println(max, "\n")
|
||||
for x := 0; x < max; x++ { |
||||
for y := 0; y < total; y++ { |
||||
|
||||
// Check if border is set
|
||||
if !t.noWhiteSpace { |
||||
fmt.Fprint(t.out, ConditionString((!t.borders.Left && y == 0), SPACE, t.pColumn)) |
||||
fmt.Fprintf(t.out, SPACE) |
||||
} |
||||
|
||||
str := columns[y][x] |
||||
|
||||
// Embedding escape sequence with column value
|
||||
if is_esc_seq { |
||||
str = format(str, t.columnsParams[y]) |
||||
} |
||||
|
||||
// This would print alignment
|
||||
// Default alignment would use multiple configuration
|
||||
switch t.columnsAlign[y] { |
||||
case ALIGN_CENTER: //
|
||||
fmt.Fprintf(t.out, "%s", Pad(str, SPACE, t.cs[y])) |
||||
case ALIGN_RIGHT: |
||||
fmt.Fprintf(t.out, "%s", PadLeft(str, SPACE, t.cs[y])) |
||||
case ALIGN_LEFT: |
||||
fmt.Fprintf(t.out, "%s", PadRight(str, SPACE, t.cs[y])) |
||||
default: |
||||
if decimal.MatchString(strings.TrimSpace(str)) || percent.MatchString(strings.TrimSpace(str)) { |
||||
fmt.Fprintf(t.out, "%s", PadLeft(str, SPACE, t.cs[y])) |
||||
} else { |
||||
fmt.Fprintf(t.out, "%s", PadRight(str, SPACE, t.cs[y])) |
||||
|
||||
// TODO Custom alignment per column
|
||||
//if max == 1 || pads[y] > 0 {
|
||||
// fmt.Fprintf(t.out, "%s", Pad(str, SPACE, t.cs[y]))
|
||||
//} else {
|
||||
// fmt.Fprintf(t.out, "%s", PadRight(str, SPACE, t.cs[y]))
|
||||
//}
|
||||
|
||||
} |
||||
} |
||||
if !t.noWhiteSpace { |
||||
fmt.Fprintf(t.out, SPACE) |
||||
} else { |
||||
fmt.Fprintf(t.out, t.tablePadding) |
||||
} |
||||
} |
||||
// Check if border is set
|
||||
// Replace with space if not set
|
||||
if !t.noWhiteSpace { |
||||
fmt.Fprint(t.out, ConditionString(t.borders.Left, t.pColumn, SPACE)) |
||||
} |
||||
fmt.Fprint(t.out, t.newLine) |
||||
} |
||||
|
||||
if t.rowLine { |
||||
t.printLine(true) |
||||
} |
||||
} |
||||
|
||||
// Print the rows of the table and merge the cells that are identical
|
||||
func (t *Table) printRowsMergeCells() { |
||||
var previousLine []string |
||||
var displayCellBorder []bool |
||||
var tmpWriter bytes.Buffer |
||||
for i, lines := range t.lines { |
||||
// We store the display of the current line in a tmp writer, as we need to know which border needs to be print above
|
||||
previousLine, displayCellBorder = t.printRowMergeCells(&tmpWriter, lines, i, previousLine) |
||||
if i > 0 { //We don't need to print borders above first line
|
||||
if t.rowLine { |
||||
t.printLineOptionalCellSeparators(true, displayCellBorder) |
||||
} |
||||
} |
||||
tmpWriter.WriteTo(t.out) |
||||
} |
||||
//Print the end of the table
|
||||
if t.rowLine { |
||||
t.printLine(true) |
||||
} |
||||
} |
||||
|
||||
// Print Row Information to a writer and merge identical cells.
|
||||
// Adjust column alignment based on type
|
||||
|
||||
func (t *Table) printRowMergeCells(writer io.Writer, columns [][]string, rowIdx int, previousLine []string) ([]string, []bool) { |
||||
// Get Maximum Height
|
||||
max := t.rs[rowIdx] |
||||
total := len(columns) |
||||
|
||||
// Pad Each Height
|
||||
pads := []int{} |
||||
|
||||
// Checking for ANSI escape sequences for columns
|
||||
is_esc_seq := false |
||||
if len(t.columnsParams) > 0 { |
||||
is_esc_seq = true |
||||
} |
||||
for i, line := range columns { |
||||
length := len(line) |
||||
pad := max - length |
||||
pads = append(pads, pad) |
||||
for n := 0; n < pad; n++ { |
||||
columns[i] = append(columns[i], " ") |
||||
} |
||||
} |
||||
|
||||
var displayCellBorder []bool |
||||
t.fillAlignment(total) |
||||
for x := 0; x < max; x++ { |
||||
for y := 0; y < total; y++ { |
||||
|
||||
// Check if border is set
|
||||
fmt.Fprint(writer, ConditionString((!t.borders.Left && y == 0), SPACE, t.pColumn)) |
||||
|
||||
fmt.Fprintf(writer, SPACE) |
||||
|
||||
str := columns[y][x] |
||||
|
||||
// Embedding escape sequence with column value
|
||||
if is_esc_seq { |
||||
str = format(str, t.columnsParams[y]) |
||||
} |
||||
|
||||
if t.autoMergeCells { |
||||
var mergeCell bool |
||||
if t.columnsToAutoMergeCells != nil { |
||||
// Check to see if the column index is in columnsToAutoMergeCells.
|
||||
if t.columnsToAutoMergeCells[y] { |
||||
mergeCell = true |
||||
} |
||||
} else { |
||||
// columnsToAutoMergeCells was not set.
|
||||
mergeCell = true |
||||
} |
||||
//Store the full line to merge mutli-lines cells
|
||||
fullLine := strings.TrimRight(strings.Join(columns[y], " "), " ") |
||||
if len(previousLine) > y && fullLine == previousLine[y] && fullLine != "" && mergeCell { |
||||
// If this cell is identical to the one above but not empty, we don't display the border and keep the cell empty.
|
||||
displayCellBorder = append(displayCellBorder, false) |
||||
str = "" |
||||
} else { |
||||
// First line or different content, keep the content and print the cell border
|
||||
displayCellBorder = append(displayCellBorder, true) |
||||
} |
||||
} |
||||
|
||||
// This would print alignment
|
||||
// Default alignment would use multiple configuration
|
||||
switch t.columnsAlign[y] { |
||||
case ALIGN_CENTER: //
|
||||
fmt.Fprintf(writer, "%s", Pad(str, SPACE, t.cs[y])) |
||||
case ALIGN_RIGHT: |
||||
fmt.Fprintf(writer, "%s", PadLeft(str, SPACE, t.cs[y])) |
||||
case ALIGN_LEFT: |
||||
fmt.Fprintf(writer, "%s", PadRight(str, SPACE, t.cs[y])) |
||||
default: |
||||
if decimal.MatchString(strings.TrimSpace(str)) || percent.MatchString(strings.TrimSpace(str)) { |
||||
fmt.Fprintf(writer, "%s", PadLeft(str, SPACE, t.cs[y])) |
||||
} else { |
||||
fmt.Fprintf(writer, "%s", PadRight(str, SPACE, t.cs[y])) |
||||
} |
||||
} |
||||
fmt.Fprintf(writer, SPACE) |
||||
} |
||||
// Check if border is set
|
||||
// Replace with space if not set
|
||||
fmt.Fprint(writer, ConditionString(t.borders.Left, t.pColumn, SPACE)) |
||||
fmt.Fprint(writer, t.newLine) |
||||
} |
||||
|
||||
//The new previous line is the current one
|
||||
previousLine = make([]string, total) |
||||
for y := 0; y < total; y++ { |
||||
previousLine[y] = strings.TrimRight(strings.Join(columns[y], " "), " ") //Store the full line for multi-lines cells
|
||||
} |
||||
//Returns the newly added line and wether or not a border should be displayed above.
|
||||
return previousLine, displayCellBorder |
||||
} |
||||
|
||||
func (t *Table) parseDimension(str string, colKey, rowKey int) []string { |
||||
var ( |
||||
raw []string |
||||
maxWidth int |
||||
) |
||||
|
||||
raw = getLines(str) |
||||
maxWidth = 0 |
||||
for _, line := range raw { |
||||
if w := DisplayWidth(line); w > maxWidth { |
||||
maxWidth = w |
||||
} |
||||
} |
||||
|
||||
// If wrapping, ensure that all paragraphs in the cell fit in the
|
||||
// specified width.
|
||||
if t.autoWrap { |
||||
// If there's a maximum allowed width for wrapping, use that.
|
||||
if maxWidth > t.mW { |
||||
maxWidth = t.mW |
||||
} |
||||
|
||||
// In the process of doing so, we need to recompute maxWidth. This
|
||||
// is because perhaps a word in the cell is longer than the
|
||||
// allowed maximum width in t.mW.
|
||||
newMaxWidth := maxWidth |
||||
newRaw := make([]string, 0, len(raw)) |
||||
|
||||
if t.reflowText { |
||||
// Make a single paragraph of everything.
|
||||
raw = []string{strings.Join(raw, " ")} |
||||
} |
||||
for i, para := range raw { |
||||
paraLines, _ := WrapString(para, maxWidth) |
||||
for _, line := range paraLines { |
||||
if w := DisplayWidth(line); w > newMaxWidth { |
||||
newMaxWidth = w |
||||
} |
||||
} |
||||
if i > 0 { |
||||
newRaw = append(newRaw, " ") |
||||
} |
||||
newRaw = append(newRaw, paraLines...) |
||||
} |
||||
raw = newRaw |
||||
maxWidth = newMaxWidth |
||||
} |
||||
|
||||
// Store the new known maximum width.
|
||||
v, ok := t.cs[colKey] |
||||
if !ok || v < maxWidth || v == 0 { |
||||
t.cs[colKey] = maxWidth |
||||
} |
||||
|
||||
// Remember the number of lines for the row printer.
|
||||
h := len(raw) |
||||
v, ok = t.rs[rowKey] |
||||
|
||||
if !ok || v < h || v == 0 { |
||||
t.rs[rowKey] = h |
||||
} |
||||
//fmt.Printf("Raw %+v %d\n", raw, len(raw))
|
||||
return raw |
||||
} |
||||
@ -1,136 +0,0 @@ |
||||
package tablewriter |
||||
|
||||
import ( |
||||
"fmt" |
||||
"strconv" |
||||
"strings" |
||||
) |
||||
|
||||
const ESC = "\033" |
||||
const SEP = ";" |
||||
|
||||
const ( |
||||
BgBlackColor int = iota + 40 |
||||
BgRedColor |
||||
BgGreenColor |
||||
BgYellowColor |
||||
BgBlueColor |
||||
BgMagentaColor |
||||
BgCyanColor |
||||
BgWhiteColor |
||||
) |
||||
|
||||
const ( |
||||
FgBlackColor int = iota + 30 |
||||
FgRedColor |
||||
FgGreenColor |
||||
FgYellowColor |
||||
FgBlueColor |
||||
FgMagentaColor |
||||
FgCyanColor |
||||
FgWhiteColor |
||||
) |
||||
|
||||
const ( |
||||
BgHiBlackColor int = iota + 100 |
||||
BgHiRedColor |
||||
BgHiGreenColor |
||||
BgHiYellowColor |
||||
BgHiBlueColor |
||||
BgHiMagentaColor |
||||
BgHiCyanColor |
||||
BgHiWhiteColor |
||||
) |
||||
|
||||
const ( |
||||
FgHiBlackColor int = iota + 90 |
||||
FgHiRedColor |
||||
FgHiGreenColor |
||||
FgHiYellowColor |
||||
FgHiBlueColor |
||||
FgHiMagentaColor |
||||
FgHiCyanColor |
||||
FgHiWhiteColor |
||||
) |
||||
|
||||
const ( |
||||
Normal = 0 |
||||
Bold = 1 |
||||
UnderlineSingle = 4 |
||||
Italic |
||||
) |
||||
|
||||
type Colors []int |
||||
|
||||
func startFormat(seq string) string { |
||||
return fmt.Sprintf("%s[%sm", ESC, seq) |
||||
} |
||||
|
||||
func stopFormat() string { |
||||
return fmt.Sprintf("%s[%dm", ESC, Normal) |
||||
} |
||||
|
||||
// Making the SGR (Select Graphic Rendition) sequence.
|
||||
func makeSequence(codes []int) string { |
||||
codesInString := []string{} |
||||
for _, code := range codes { |
||||
codesInString = append(codesInString, strconv.Itoa(code)) |
||||
} |
||||
return strings.Join(codesInString, SEP) |
||||
} |
||||
|
||||
// Adding ANSI escape sequences before and after string
|
||||
func format(s string, codes interface{}) string { |
||||
var seq string |
||||
|
||||
switch v := codes.(type) { |
||||
|
||||
case string: |
||||
seq = v |
||||
case []int: |
||||
seq = makeSequence(v) |
||||
case Colors: |
||||
seq = makeSequence(v) |
||||
default: |
||||
return s |
||||
} |
||||
|
||||
if len(seq) == 0 { |
||||
return s |
||||
} |
||||
return startFormat(seq) + s + stopFormat() |
||||
} |
||||
|
||||
// Adding header colors (ANSI codes)
|
||||
func (t *Table) SetHeaderColor(colors ...Colors) { |
||||
if t.colSize != len(colors) { |
||||
panic("Number of header colors must be equal to number of headers.") |
||||
} |
||||
for i := 0; i < len(colors); i++ { |
||||
t.headerParams = append(t.headerParams, makeSequence(colors[i])) |
||||
} |
||||
} |
||||
|
||||
// Adding column colors (ANSI codes)
|
||||
func (t *Table) SetColumnColor(colors ...Colors) { |
||||
if t.colSize != len(colors) { |
||||
panic("Number of column colors must be equal to number of headers.") |
||||
} |
||||
for i := 0; i < len(colors); i++ { |
||||
t.columnsParams = append(t.columnsParams, makeSequence(colors[i])) |
||||
} |
||||
} |
||||
|
||||
// Adding column colors (ANSI codes)
|
||||
func (t *Table) SetFooterColor(colors ...Colors) { |
||||
if len(t.footers) != len(colors) { |
||||
panic("Number of footer colors must be equal to number of footer.") |
||||
} |
||||
for i := 0; i < len(colors); i++ { |
||||
t.footerParams = append(t.footerParams, makeSequence(colors[i])) |
||||
} |
||||
} |
||||
|
||||
func Color(colors ...int) []int { |
||||
return colors |
||||
} |
||||
@ -1,93 +0,0 @@ |
||||
// Copyright 2014 Oleku Konko All rights reserved.
|
||||
// Use of this source code is governed by a MIT
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
// This module is a Table Writer API for the Go Programming Language.
|
||||
// The protocols were written in pure Go and works on windows and unix systems
|
||||
|
||||
package tablewriter |
||||
|
||||
import ( |
||||
"math" |
||||
"regexp" |
||||
"strings" |
||||
|
||||
"github.com/mattn/go-runewidth" |
||||
) |
||||
|
||||
var ansi = regexp.MustCompile("\033\\[(?:[0-9]{1,3}(?:;[0-9]{1,3})*)?[m|K]") |
||||
|
||||
func DisplayWidth(str string) int { |
||||
return runewidth.StringWidth(ansi.ReplaceAllLiteralString(str, "")) |
||||
} |
||||
|
||||
// Simple Condition for string
|
||||
// Returns value based on condition
|
||||
func ConditionString(cond bool, valid, inValid string) string { |
||||
if cond { |
||||
return valid |
||||
} |
||||
return inValid |
||||
} |
||||
|
||||
func isNumOrSpace(r rune) bool { |
||||
return ('0' <= r && r <= '9') || r == ' ' |
||||
} |
||||
|
||||
// Format Table Header
|
||||
// Replace _ , . and spaces
|
||||
func Title(name string) string { |
||||
origLen := len(name) |
||||
rs := []rune(name) |
||||
for i, r := range rs { |
||||
switch r { |
||||
case '_': |
||||
rs[i] = ' ' |
||||
case '.': |
||||
// ignore floating number 0.0
|
||||
if (i != 0 && !isNumOrSpace(rs[i-1])) || (i != len(rs)-1 && !isNumOrSpace(rs[i+1])) { |
||||
rs[i] = ' ' |
||||
} |
||||
} |
||||
} |
||||
name = string(rs) |
||||
name = strings.TrimSpace(name) |
||||
if len(name) == 0 && origLen > 0 { |
||||
// Keep at least one character. This is important to preserve
|
||||
// empty lines in multi-line headers/footers.
|
||||
name = " " |
||||
} |
||||
return strings.ToUpper(name) |
||||
} |
||||
|
||||
// Pad String
|
||||
// Attempts to place string in the center
|
||||
func Pad(s, pad string, width int) string { |
||||
gap := width - DisplayWidth(s) |
||||
if gap > 0 { |
||||
gapLeft := int(math.Ceil(float64(gap / 2))) |
||||
gapRight := gap - gapLeft |
||||
return strings.Repeat(string(pad), gapLeft) + s + strings.Repeat(string(pad), gapRight) |
||||
} |
||||
return s |
||||
} |
||||
|
||||
// Pad String Right position
|
||||
// This would place string at the left side of the screen
|
||||
func PadRight(s, pad string, width int) string { |
||||
gap := width - DisplayWidth(s) |
||||
if gap > 0 { |
||||
return s + strings.Repeat(string(pad), gap) |
||||
} |
||||
return s |
||||
} |
||||
|
||||
// Pad String Left position
|
||||
// This would place string at the right side of the screen
|
||||
func PadLeft(s, pad string, width int) string { |
||||
gap := width - DisplayWidth(s) |
||||
if gap > 0 { |
||||
return strings.Repeat(string(pad), gap) + s |
||||
} |
||||
return s |
||||
} |
||||
@ -1,99 +0,0 @@ |
||||
// Copyright 2014 Oleku Konko All rights reserved.
|
||||
// Use of this source code is governed by a MIT
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
// This module is a Table Writer API for the Go Programming Language.
|
||||
// The protocols were written in pure Go and works on windows and unix systems
|
||||
|
||||
package tablewriter |
||||
|
||||
import ( |
||||
"math" |
||||
"strings" |
||||
|
||||
"github.com/mattn/go-runewidth" |
||||
) |
||||
|
||||
var ( |
||||
nl = "\n" |
||||
sp = " " |
||||
) |
||||
|
||||
const defaultPenalty = 1e5 |
||||
|
||||
// Wrap wraps s into a paragraph of lines of length lim, with minimal
|
||||
// raggedness.
|
||||
func WrapString(s string, lim int) ([]string, int) { |
||||
words := strings.Split(strings.Replace(s, nl, sp, -1), sp) |
||||
var lines []string |
||||
max := 0 |
||||
for _, v := range words { |
||||
max = runewidth.StringWidth(v) |
||||
if max > lim { |
||||
lim = max |
||||
} |
||||
} |
||||
for _, line := range WrapWords(words, 1, lim, defaultPenalty) { |
||||
lines = append(lines, strings.Join(line, sp)) |
||||
} |
||||
return lines, lim |
||||
} |
||||
|
||||
// WrapWords is the low-level line-breaking algorithm, useful if you need more
|
||||
// control over the details of the text wrapping process. For most uses,
|
||||
// WrapString will be sufficient and more convenient.
|
||||
//
|
||||
// WrapWords splits a list of words into lines with minimal "raggedness",
|
||||
// treating each rune as one unit, accounting for spc units between adjacent
|
||||
// words on each line, and attempting to limit lines to lim units. Raggedness
|
||||
// is the total error over all lines, where error is the square of the
|
||||
// difference of the length of the line and lim. Too-long lines (which only
|
||||
// happen when a single word is longer than lim units) have pen penalty units
|
||||
// added to the error.
|
||||
func WrapWords(words []string, spc, lim, pen int) [][]string { |
||||
n := len(words) |
||||
|
||||
length := make([][]int, n) |
||||
for i := 0; i < n; i++ { |
||||
length[i] = make([]int, n) |
||||
length[i][i] = runewidth.StringWidth(words[i]) |
||||
for j := i + 1; j < n; j++ { |
||||
length[i][j] = length[i][j-1] + spc + runewidth.StringWidth(words[j]) |
||||
} |
||||
} |
||||
nbrk := make([]int, n) |
||||
cost := make([]int, n) |
||||
for i := range cost { |
||||
cost[i] = math.MaxInt32 |
||||
} |
||||
for i := n - 1; i >= 0; i-- { |
||||
if length[i][n-1] <= lim { |
||||
cost[i] = 0 |
||||
nbrk[i] = n |
||||
} else { |
||||
for j := i + 1; j < n; j++ { |
||||
d := lim - length[i][j-1] |
||||
c := d*d + cost[j] |
||||
if length[i][j-1] > lim { |
||||
c += pen // too-long lines get a worse penalty
|
||||
} |
||||
if c < cost[i] { |
||||
cost[i] = c |
||||
nbrk[i] = j |
||||
} |
||||
} |
||||
} |
||||
} |
||||
var lines [][]string |
||||
i := 0 |
||||
for i < n { |
||||
lines = append(lines, words[i:nbrk[i]]) |
||||
i = nbrk[i] |
||||
} |
||||
return lines |
||||
} |
||||
|
||||
// getLines decomposes a multiline string into a slice of strings.
|
||||
func getLines(s string) []string { |
||||
return strings.Split(s, nl) |
||||
} |
||||
@ -0,0 +1,24 @@ |
||||
module github.com/parquet-go/parquet-go |
||||
|
||||
go 1.23.4 |
||||
|
||||
toolchain go1.24.0 |
||||
|
||||
tool golang.org/x/tools/gopls/internal/analysis/modernize/cmd/modernize |
||||
|
||||
require ( |
||||
github.com/andybalholm/brotli v1.1.1 |
||||
github.com/google/uuid v1.6.0 |
||||
github.com/hexops/gotextdiff v1.0.3 |
||||
github.com/klauspost/compress v1.18.0 |
||||
github.com/pierrec/lz4/v4 v4.1.22 |
||||
golang.org/x/sys v0.30.0 |
||||
google.golang.org/protobuf v1.36.5 |
||||
) |
||||
|
||||
require ( |
||||
golang.org/x/mod v0.23.0 // indirect |
||||
golang.org/x/sync v0.11.0 // indirect |
||||
golang.org/x/tools v0.30.1-0.20250221230316-5055f70f240c // indirect |
||||
golang.org/x/tools/gopls v0.18.1 // indirect |
||||
) |
||||
@ -0,0 +1,26 @@ |
||||
github.com/andybalholm/brotli v1.1.1 h1:PR2pgnyFznKEugtsUo0xLdDop5SKXd5Qf5ysW+7XdTA= |
||||
github.com/andybalholm/brotli v1.1.1/go.mod h1:05ib4cKhjx3OQYUY22hTVd34Bc8upXjOLL2rKwwZBoA= |
||||
github.com/google/go-cmp v0.6.0 h1:ofyhxvXcZhMsU5ulbFiLKl/XBFqE1GSq7atu8tAmTRI= |
||||
github.com/google/go-cmp v0.6.0/go.mod h1:17dUlkBOakJ0+DkrSSNjCkIjxS6bF9zb3elmeNGIjoY= |
||||
github.com/google/uuid v1.6.0 h1:NIvaJDMOsjHA8n1jAhLSgzrAzy1Hgr+hNrb57e+94F0= |
||||
github.com/google/uuid v1.6.0/go.mod h1:TIyPZe4MgqvfeYDBFedMoGGpEw/LqOeaOT+nhxU+yHo= |
||||
github.com/hexops/gotextdiff v1.0.3 h1:gitA9+qJrrTCsiCl7+kh75nPqQt1cx4ZkudSTLoUqJM= |
||||
github.com/hexops/gotextdiff v1.0.3/go.mod h1:pSWU5MAI3yDq+fZBTazCSJysOMbxWL1BSow5/V2vxeg= |
||||
github.com/klauspost/compress v1.18.0 h1:c/Cqfb0r+Yi+JtIEq73FWXVkRonBlf0CRNYc8Zttxdo= |
||||
github.com/klauspost/compress v1.18.0/go.mod h1:2Pp+KzxcywXVXMr50+X0Q/Lsb43OQHYWRCY2AiWywWQ= |
||||
github.com/pierrec/lz4/v4 v4.1.22 h1:cKFw6uJDK+/gfw5BcDL0JL5aBsAFdsIT18eRtLj7VIU= |
||||
github.com/pierrec/lz4/v4 v4.1.22/go.mod h1:gZWDp/Ze/IJXGXf23ltt2EXimqmTUXEy0GFuRQyBid4= |
||||
github.com/xyproto/randomstring v1.0.5 h1:YtlWPoRdgMu3NZtP45drfy1GKoojuR7hmRcnhZqKjWU= |
||||
github.com/xyproto/randomstring v1.0.5/go.mod h1:rgmS5DeNXLivK7YprL0pY+lTuhNQW3iGxZ18UQApw/E= |
||||
golang.org/x/mod v0.23.0 h1:Zb7khfcRGKk+kqfxFaP5tZqCnDZMjC5VtUBs87Hr6QM= |
||||
golang.org/x/mod v0.23.0/go.mod h1:6SkKJ3Xj0I0BrPOZoBy3bdMptDDU9oJrpohJ3eWZ1fY= |
||||
golang.org/x/sync v0.11.0 h1:GGz8+XQP4FvTTrjZPzNKTMFtSXH80RAzG+5ghFPgK9w= |
||||
golang.org/x/sync v0.11.0/go.mod h1:Czt+wKu1gCyEFDUtn0jG5QVvpJ6rzVqr5aXyt9drQfk= |
||||
golang.org/x/sys v0.30.0 h1:QjkSwP/36a20jFYWkSue1YwXzLmsV5Gfq7Eiy72C1uc= |
||||
golang.org/x/sys v0.30.0/go.mod h1:/VUhepiaJMQUp4+oa/7Zr1D23ma6VTLIYjOOTFZPUcA= |
||||
golang.org/x/tools v0.30.1-0.20250221230316-5055f70f240c h1:Ja/5gV5a9Vvho3p2NC/T2TtxhHjrWS/2DvCKMvA0a+Y= |
||||
golang.org/x/tools v0.30.1-0.20250221230316-5055f70f240c/go.mod h1:c347cR/OJfw5TI+GfX7RUPNMdDRRbjvYTS0jPyvsVtY= |
||||
golang.org/x/tools/gopls v0.18.1 h1:2xJBNzdImS5u/kV/ZzqDLSvlBSeZX+pWY9uKVP7Pask= |
||||
golang.org/x/tools/gopls v0.18.1/go.mod h1:UdNu0zeGjkmjL9L20QDszXu9tP2798pUIHC980kOBrI= |
||||
google.golang.org/protobuf v1.36.5 h1:tPhr+woSbjfYvY6/GPufUoYizxw1cF/yFoxJ2fmpwlM= |
||||
google.golang.org/protobuf v1.36.5/go.mod h1:9fA7Ob0pmnwhb644+1+CVWFRbNajQ6iRojtC/QF5bRE= |
||||
Loading…
Reference in new issue